
一、BettaFish 简介
项目地址:https://github.com/666ghj/BettaFish
✅ 项目简介
- BettaFish 是一个 多 Agent 舆情分析助手,目标是打破信息茧房,恢复原始舆情,并预测未来舆情走向。
- 项目号称 纯 Python 实现,不依赖大框架。
- 主语言是 Python (~92.8%)。
- 采用 GPL‑2.0 许可证。
🧱 架构与模块
主要模块如下:
- QueryEngine:负责广度的新闻/网络搜索,国内外舆情数据采集。
- MediaEngine:多模态内容分析,包括短视频、图片、文字,支持抖音、快手等平台。
- InsightEngine:私有数据库挖掘与情感分析。
- ReportEngine:生成多轮分析报告,如“社会热点事件分析”、“品牌舆情监控”等。
- ForumEngine:类似论坛机制,让不同 Agent 讨论/反思,避免单一模型偏差。
- MindSpider:爬虫系统,用于抓取话题、新闻、评论等信息。
工作流程:
- 用户通过 Flask 提交查询。
- 多个 Agent(Query、Media、Insight)并行执行分析。
- ForumEngine 让 Agent 间讨论、反思,形成多视角结果。
- ReportEngine 整合结果并生成最终报告。
🎯 功能亮点
- 24×7 AI 爬虫覆盖国内外 10+ 主流社交媒体及海量评论。
- 多模型协作:5 种专门 Agent + 微调模型 + 统计模型等。
- 多模态分析:不仅是文字,还有短视频、搜索卡片(天气、股票、日历等)。
- “论坛”机制避免单模型思维偏差。
- 可融合企业内部业务数据进行分析。
- 轻量可扩展,纯 Python 模块化设计,易于集成自定义模型和业务逻辑。
🛠 快速上手 & 需求
- 操作系统:Windows / Linux / MacOS;推荐 Python 3.9+
- 启动方式:Docker Compose:
docker compose up -d - 数据库:推荐 PostgreSQL(MySQL 可行但需调整)
- 配置:复制
.env.example→.env,配置数据库连接 + LLM API Key 等 - 单独 Agent 测试:支持 Streamlit 前端,分别运行 QueryEngine、MediaEngine、InsightEngine
二、BettaFish 部署
1、创建文件夹及文件
mkdir /workplaces/bettafish
cd /workplaces/bettafish
nano .env
# 不需要写入内容,保存退出即可
nano docker-compose.yml2、docker-compose.yml
完全按照官方文件,注意修改镜像源为被注释的南京大学镜像,否则全文件大约10个G,拉取较慢。
version: "3.9"
services:
bettafish:
# image: ghcr.io/666ghj/bettafish:latest
# Speed up mirror
image: ghcr.nju.edu.cn/666ghj/bettafish:latest
container_name: bettafish
restart: unless-stopped
environment:
- PYTHONUNBUFFERED=1
- STREAMLIT_SERVER_ENABLE_FILE_WATCHER=false
ports:
- "5000:5000"
- "8501:8501"
- "8502:8502"
- "8503:8503"
volumes:
- ./logs:/app/logs
- ./final_reports:/app/final_reports
- ./insight_engine_streamlit_reports:/app/insight_engine_streamlit_reports
- ./media_engine_streamlit_reports:/app/media_engine_streamlit_reports
- ./query_engine_streamlit_reports:/app/query_engine_streamlit_reports
db:
image: postgres:15
container_name: bettafish-db
restart: unless-stopped
env_file:
- .env
environment:
POSTGRES_USER: ${POSTGRES_USER:-bettafish}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD:-bettafish}
POSTGRES_DB: ${POSTGRES_DB:-bettafish}
ports:
- "${POSTGRES_PORT:-5444}:5432"
volumes:
- ./db_data:/var/lib/postgresql/data3、访问 Web 界面
docker-compose.yml,映射了以下端口:
| 端口 | 功能 |
|---|---|
| 5000 | Flask 主应用 |
| 8501 | QueryEngine Streamlit |
| 8502 | MediaEngine Streamlit |
| 8503 | InsightEngine Streamlit |
三、功能预研
访问主应用5000端口:
http://192.168.202.180:5000/1、配置数据库
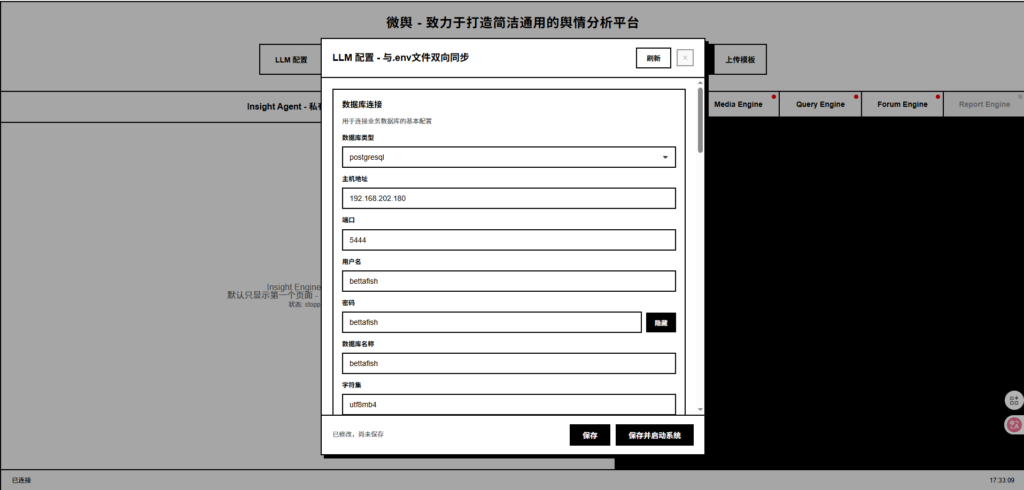
如果你使用默认 .env 文件,PostgreSQL 已经初始化好:
- 数据库:
bettafish - 用户:
bettafish - 密码:
bettafish - 端口:
5444(映射到宿主机)
你可以通过 psql 或 PgAdmin 连接数据库,查看数据。
# 进入容器
docker exec -it bettafish-db psql -U bettafish -d bettafish1、数据库连接配置
——1——
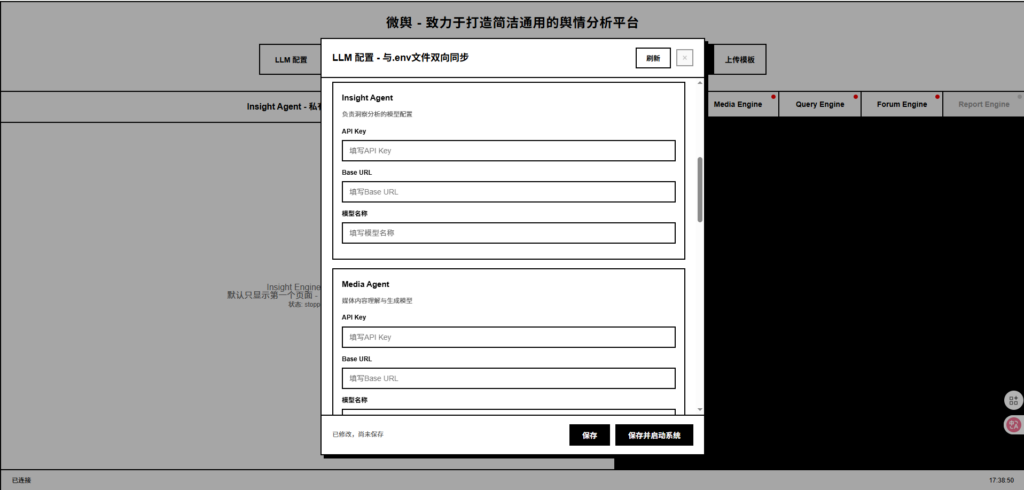
2、BettaFish 的 LLM/Agent 模型和外部检索工具配置界面
——2——
BettaFish 是一个“多 Agent + LLM + 数据抓取”系统,每个 Agent 都是一个独立的模型实例或调用接口:
| Agent | 作用 | 需要的配置 |
|---|---|---|
| Insight Agent | 洞察分析 | LLM API Key、Base URL、模型名称 |
| Media Agent | 短视频/图片分析 | LLM API Key、Base URL、模型名称 |
| Query Agent | 搜索与信息汇总 | LLM API Key、Base URL、模型名称 |
| Report Agent | 报告生成 | LLM API Key、Base URL、模型名称 |
| Forum Host | Agent 间协作 | LLM API Key、Base URL、模型名称 |
| Keyword Optimizer | SQL/关键词优化 | LLM API Key、Base URL、模型名称 |
| 外部检索工具 | 联动搜索/网站抓取 | Tavily/Bocha 等 API Key |
这些 API Key 和 Base URL 都是外部服务提供的,比如 OpenAI GPT 系列、OpenAI 兼容 API、或者你自己部署的私有 LLM。
系统自带吗?
- 不自带。系统只提供调用逻辑,你必须自己申请或配置 LLM 服务。
- 如果没有 API Key 或模型 URL,这些 Agent 无法运行,你提交查询会报错或返回空。
如果你只是想 最小化配置、保证系统可启动并能跑一个测试分析流程,其实只需要填 核心的一个或两个 Agent 的 LLM Key,其他可暂时留空。
建议最小配置
| 模块 | 是否必须 | 说明 |
|---|---|---|
| Query Agent | ✅ 必填 | 搜索与信息汇总,是系统获取数据的核心,如果没有它,系统无法抓取文本信息进行分析。 |
| 外部检索工具 | ✅ 必填 | 联动搜索/网站抓取,Tavily/Bocha |
| Report Agent | ✅ 建议填 | 报告生成模块,如果你想看到最终 PDF/HTML 报告,需要这个 Agent。 |
目前只搭建了Query Engine和Report Engine两大模块
这两个模块实现了可以爬数据查询+输出报告两大功能,使用同一个大模型 API Key
还有一个必须的是Tavily API Key外部检索工具
联动搜索引擎、网站抓取等在线服务
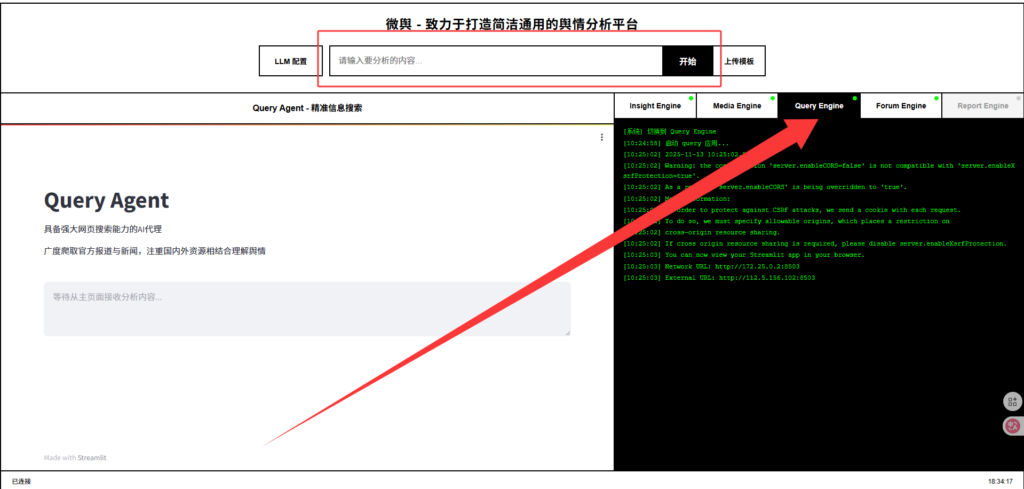
3、使用流程
- 在 Flask 主界面提交查询:输入你想分析的舆情事件或关键词。
- Agent 并行分析:QueryEngine、MediaEngine、InsightEngine 会抓取信息并分析。
- ForumEngine 讨论:不同 Agent 对信息进行多角度反思和讨论。
- 生成报告:ReportEngine 输出 PDF 或 HTML 报告到
/final_reports。
日志和报告路径对应你的 docker-compose.yml:
./logs # 系统日志
./final_reports # 最终分析报告
./query_engine_streamlit_reports # QueryEngine 报告
./media_engine_streamlit_reports # MediaEngine 报告
./insight_engine_streamlit_reports # InsightEngine 报告你可以在宿主机直接查看。
4、测试
点击Query Engine(目前只配置了这个),输入想要搜索的资料
——3——
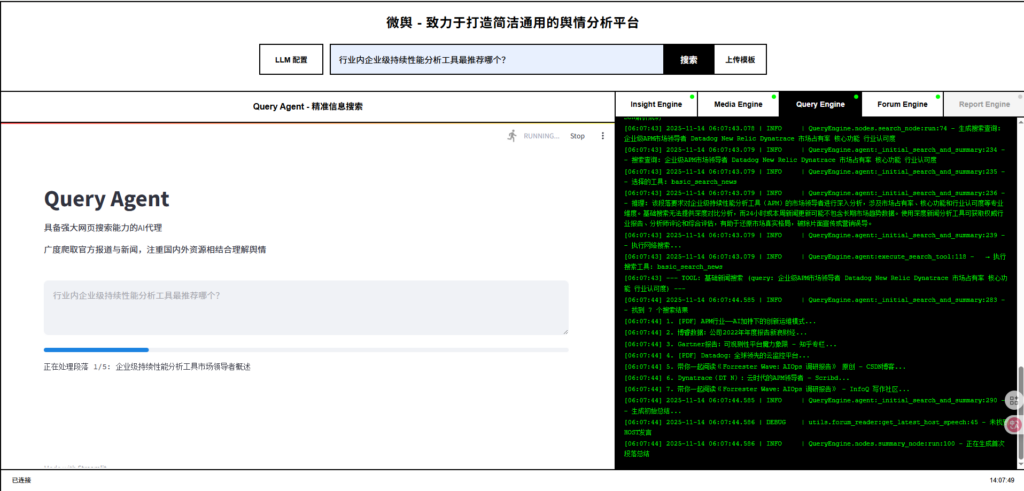
等待……爬取过程比较慢
查看结果方式:
1、成功左边会生成网页版报告
2、可以点击左边右上角的三个点,选择print,输出pdf文件
3、/workplaces/bettafish/query_engine_streamlit_reports/
该目录下会保存生成的报告Markdown格式【效果更好】和JSON格式
——4——
四、常见问题
1、费用情况
(1)大模型 API key 费用
主流大模型基本支持,详见各官网。所有 LLM 调用使用 OpenAI 的 API 接口标准
(2)Tavily
费用
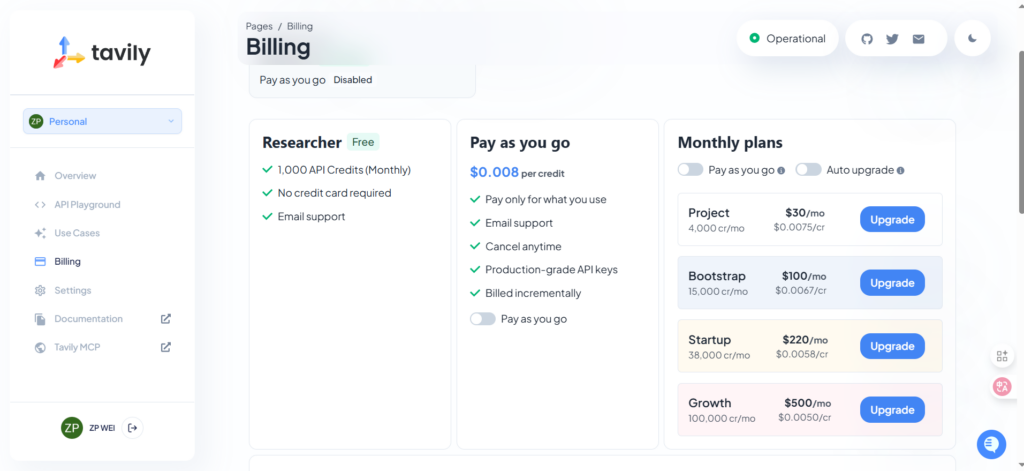
——5——
体验量
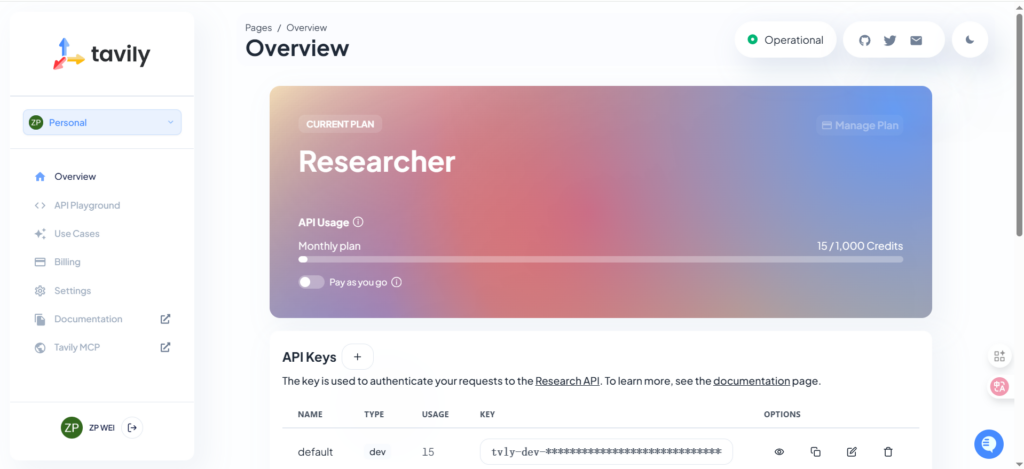
——6——
(3)博查
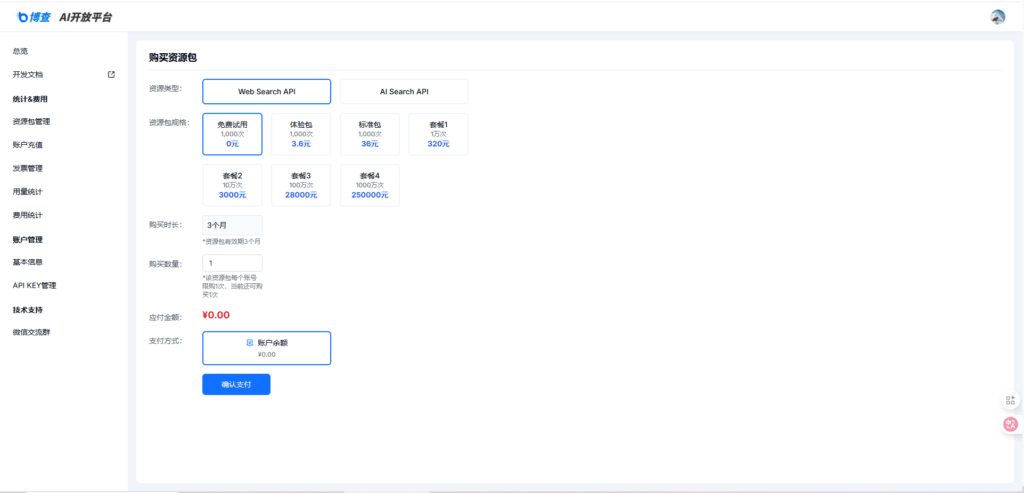
——7——
补充费用情况
https://bocha-ai.feishu.cn/wiki/JYSbwzdPIiFnz4kDYPXcHSDrnZb
2、关于爬虫BettaFish法律风险问题
❌ BettaFish 本身不会去直接访问网页
✔ 它只调用 Tavily / Bocha 等“搜索服务”
✔ 真正去爬网页的是 Tavily、Bocha 的服务器
✔ 你的企业服务器不会主动对外抓取目标网页
BettaFish 的 Query Agent 并不是爬虫,它不会自己访问网页,也不会使用你公司服务器的公网 IP 去爬取网站内容。
它依赖的是 第三方搜索 API(Tavily)。
也就是说:
🔥 所有外部网页搜索都是 Tavily 的服务器执行的,不是你的服务器执行的。
你企业服务器只是发起:
你的服务器 → Tavily API → Tavily 发起搜索/爬取 → 结果返回给你
所以:
| 项目 | 发起方 | 你的公司 IP 是否暴露 |
|---|---|---|
| Tavily 搜索查询 | 你的服务器 → Tavily | ❌ 不暴露,公司 IP 只被 Tavily 看到 |
| 网页爬取 | Tavily → 各种网站 | ❌ 不暴露,你的服务器完全不会访问被查询的网站 |
| Query Agent 生成报告 | 全在本地 | ❌ 完全不暴露 |
3、为什么选择BettaFish?
🌟 1)BettaFish 的优势(相对于“直接用大模型搜索”)
| 能力 | 直接问大模型 | BettaFish | 说明 |
|---|---|---|---|
| 实时性 | ❌大模型不能实时联网 | ✔️依靠 Tavily 实时搜索 | LLM知识落后,BettaFish 能实时查 |
| 搜索深度 | ❌只给你一句话结果 | ✔️自动多轮搜索/扩展关键词 | 自动往下挖、查几十个来源 |
| 系统化报告 | ❌输出碎片化内容 | ✔️生成结构化分析报告 | 有标题、目录、分析结论 |
| 多Agent协同 | ❌单模型不具备 | ✔️Query/Report 角色分工 | 类似多人团队做调研 |
| 可控流程 | ❌不可控 | ✔️明确工作流(检索→分析→报告) | 过程透明,可审计 |
总结一句话:
BettaFish = 大模型 × 实时搜索 × 多轮调研 × 自动报告生成
是“大模型 + 搜索引擎”的增强版,不是普通对话式 AI。
🔍 2)Tavily 是什么?为什么 BettaFish 离不开 Tavily?
Tavily 是一个 专门为 AI 应用设计的专业 Web 搜索 API。
🧠 主要功能
- 从 全球网页 搜集数据(不限于 Google/Bing)
- 自动过滤广告、SEO 垃圾站
- 自动做网页摘要
- 自动排序并返回最权威来源
- 输出 结构化 JSON(适用于 AI 再处理)
不像 Google/Bing 那样返回网页链接,Tavily 返回的是:
[
{
"title": "XXX 新闻",
"content": "摘要文本…",
"url": "xxx.com"
}
]对 AI 非常友好。
⚙️ 3)Tavily 的工作原理(简单版)
你输入一个主题:
“OpenAI 最新发布的模型”
Tavily 会:
① 搜索全网来源
Google、Bing、News、博客、社区等数据源混合检索。
② 自动抽取网页正文
自动剥离广告、导航、评论等噪音。
③ 自动摘要压缩
把网页几千字内容压成几百字。
④ 质量评分与排序
- 来源权威性
- 文本可信度
- 信息新鲜度
- 是否重复
⑤ 返回结构化结果给 AI
大模型拿到的不是一堆URL,而是干净的文本。
所以 Tavily + 大模型 = 实时 + 干净的数据输入
而不是让模型自己胡扯。
🆚 4)Tavily 与「让大模型自己搜索」相比的优势
大模型本身不具备网络爬虫能力,它只能:
- 胡乱猜测搜索结果
- 输出不存在的新闻 / 链接
- 模拟“仿造的网页内容”
大模型自己无法联网
所有“联网模式”其实都只是调用外部 API。
BettaFish 选 Tavily 因为:
- Tavily 干净、可控、低成本
- 返回结构化摘要
- 已对接各类 AI 框架
- 速度快
直接让大模型“搜索”其实是在骗自己。
⚠️ 5)为什么你觉得 BettaFish 的结果“不准确”?
有 4 个常见原因:
1)Tavily 的英文搜索强,中文弱
它是美国团队做的,中文网页覆盖少。
→ 对中文舆情效果明显不如 Bing API / 自定义爬虫。
2)BettaFish 默认爬取深度不高
Query Agent 默认只跑几轮搜索
→ 信息覆盖率不够。
3)LLM 质量决定“汇总质量”
如果你使用的模型是:
- qwen1.5
- glm3 低版本
- gpt-3.5
它把多网页内容合成报告时容易丢失细节。
4)提取事实能力有限
大模型天然会:
- 总结过度
- 思维跳跃
- 合并不同来源导致错误
这不是 BettaFish 的问题,而是 LLM 的普遍限制。
📌 总结一句话
BettaFish 的真正价值:
自动化地帮你完成“搜索 → 过滤 → 收集 → 整理 → 报告”的全链路。
Tavily 的价值:
提供实时、干净、结构化的网页内容,让大模型不再胡编。
附:官方 BettaFish 一次完整分析流程
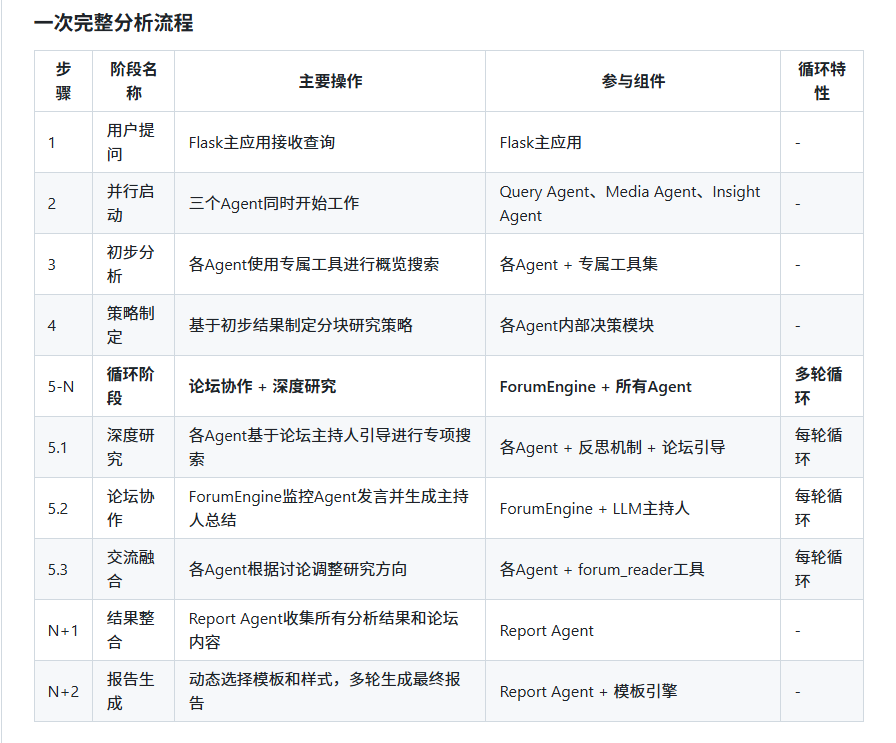
——8——
4、LLM配置-更新配置生效方式
注意:一定要重启,再次打开Web页面出现“保存并启动系统”
(1)点击左上角LLM配置
(2)更新完新的秘钥——>点击“保存”
(3)重启
docker-compose restart battafish(4)重新进入battafish
确认一下秘钥等配置没有问题——>点击“保存并启动系统”
作者
fffff@xf.nn


