
一、Pyroscope 简介
Pyroscope(持续性能分析工具)
Pyroscope 是一个开源的 持续性能分析(Continuous Profiling)工具,用于实时监控应用程序在运行时的性能状况,帮助开发者发现热点函数、优化 CPU 和内存使用效率。它由 Grafana Labs 维护,并且支持多语言的集成。
主要特点
- 持续采样 Pyroscope 会在应用运行时自动采集调用栈信息,包括 CPU 占用、内存分配、Goroutine 或线程状态等,并以非常低的开销持续收集数据。
- 多语言支持 提供丰富的 SDK,支持 Go、Python、Java、Ruby、C/C++ 等主流开发语言。不同语言的 SDK 可以直接嵌入业务代码,实现对特定函数或模块的采样和标签化分析。
- 可视化分析
- Flame Graph(火焰图):显示函数调用耗时,按调用层级排列,直观展示热点函数。
- Diff Flame Graph(对比火焰图):比较不同时间段或版本的性能差异,红色表示耗时增加,蓝色表示耗时下降。
- Sandwich View(夹心视图):结合 Top-down 和 Bottom-up 的调用栈分析,可同时看到函数的调用来源和调用消耗。
- 标签与分组 可以为应用或函数自定义标签(Tag),实现不同模块或服务的分组管理。企业研发团队可根据标签查看自己负责模块的性能数据,避免所有人看到所有人的代码性能。
- 低开销、高性能 Pyroscope 的采样机制采用周期性采样(如 10ms 一次),不会像传统 profiling 工具那样对业务性能造成明显影响,适合在生产环境长期运行。
部署方式
- 服务端(Pyroscope Server)
- 用于收集、存储和展示性能数据。
- 支持 Docker 或直接下载二进制文件安装。
- 客户端 / Agent
- 将 SDK 集成到应用中,定期向服务端发送采样数据。
- 不同应用可以使用不同
ApplicationName和标签,数据统一汇聚到 Pyroscope Server。
- 可选可视化(Grafana)
- Pyroscope 可以作为数据源接入 Grafana,实现更丰富的仪表板展示和团队级监控。
应用场景
- 性能回归检测:发布新版本前,对比 Diff Flame Graph 发现性能下降的函数。
- 研发团队协作:多人团队可以按模块或服务查看自己的热点函数,优化效率。
- 生产环境监控:实时监控关键服务,快速定位 CPU 或内存瓶颈。
- 微服务分析:对分布式服务或多个实例的调用栈进行统一采集和分析。
Pyroscope 能监控的主要属性
Pyroscope 本质上是 函数级别的性能采样器,它关注以下方面:
| 类型 | 属性 | 描述 | 举例 |
|---|---|---|---|
| CPU Profiling | CPU 时间 | 每个函数在 CPU 上消耗的时间 | 你代码中 doWork() 占用了多少 CPU |
| Memory Allocation | 内存分配 | 每个函数分配了多少堆内存 | new 或 make 调用消耗内存量 |
| Goroutine / Thread Profiling | 并发状态 | Go 中的 goroutine 活跃情况,线程状态 | 活跃、阻塞、等待等 |
| Custom Labels / Tags | 自定义维度 | 可以自己在代码里打标签 | pyroscope.Tag("service", "teamA") |
| Other Runtime Metrics | 高级运行时 | 比如 Python 的垃圾回收、Java 的 JVM 堆栈 | 需要对应语言 SDK 支持 |
注意:Pyroscope 采集的是调用栈信息,而不是直接的“CPU %”或者“内存 MB”。它把调用栈信息聚合后,在 Grafana 里展示成 flamegraph、top-down 或时间序列图。
二、Pyroscope + Grafana 集成环境部署
🧩 目标
使用 docker-compose 同时部署:
- Pyroscope Server(持续性能分析后端)
- Grafana(可视化界面,已自动集成 Pyroscope 插件)
🧱 docker-compose.yml
请在任意空文件夹下创建以下文件:
version: "3.9"
services:
pyroscope:
image: grafana/pyroscope:latest
container_name: pyroscope
ports:
- "4040:4040"
networks:
- pyroscope-net
volumes:
- ./pyroscope-data:/var/lib/pyroscope
restart: unless-stopped
grafana:
image: grafana/grafana:main
container_name: grafana
ports:
- "3000:3000"
environment:
- GF_PLUGINS_PREINSTALL_SYNC=grafana-pyroscope-app
- GF_AUTH_ANONYMOUS_ENABLED=true
- GF_AUTH_ANONYMOUS_ORG_ROLE=Admin
- GF_AUTH_DISABLE_LOGIN_FORM=true
depends_on:
- pyroscope
networks:
- pyroscope-net
restart: unless-stopped
networks:
pyroscope-net:
driver: bridge注意:正式环境中需要考虑权限问题,pyroscope本身不具有权限管理功能,权限管理主要依靠grafana
正式环境中不推荐使用以下环境变量
environment:
- GF_PLUGINS_PREINSTALL_SYNC=grafana-pyroscope-app
- GF_AUTH_ANONYMOUS_ENABLED=true
- GF_AUTH_ANONYMOUS_ORG_ROLE=Admin
- GF_AUTH_DISABLE_LOGIN_FORM=true| 变量 | 含义 |
|---|---|
GF_AUTH_ANONYMOUS_ENABLED=true | 开启匿名访问,任何人打开 Grafana 都能直接访问 |
GF_AUTH_ANONYMOUS_ORG_ROLE=Admin | 匿名用户拥有 Admin 权限(危险,生产环境不建议) |
GF_AUTH_DISABLE_LOGIN_FORM=true | 禁用登录表单,意味着即使你点击“登录”,也看不到表单 |
🚀 启动命令
在该目录下执行:
docker-compose up -d检查容器是否启动成功:
docker ps🌐 访问地址
| 服务 | 地址 | 默认端口 | 说明 |
|---|---|---|---|
| Pyroscope | http://localhost:4040 | 4040 | 性能数据分析界面 |
| Grafana | http://localhost:3000 | 3000 | 可视化界面(已集成 Pyroscope 插件) |
若部署在远程服务器,请将
localhost替换为服务器 IP。
⚙️ Grafana 配置 Pyroscope 数据源
参照官网:https://grafana.com/docs/grafana/latest/datasources/pyroscope/configure-pyroscope-data-source/
进入 Grafana(默认免登录): 👉 http://localhost:3000/datasources
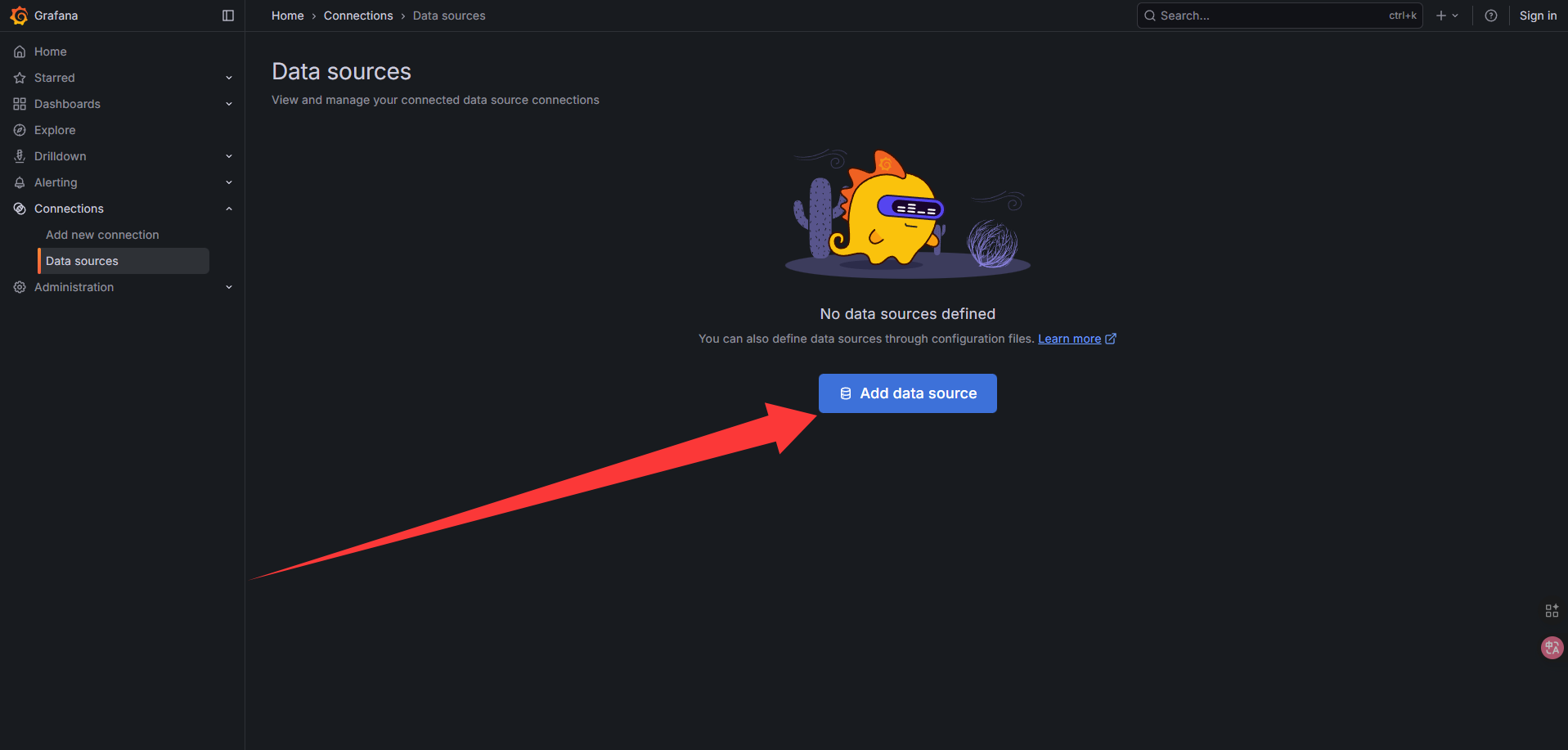
——1——
——2——
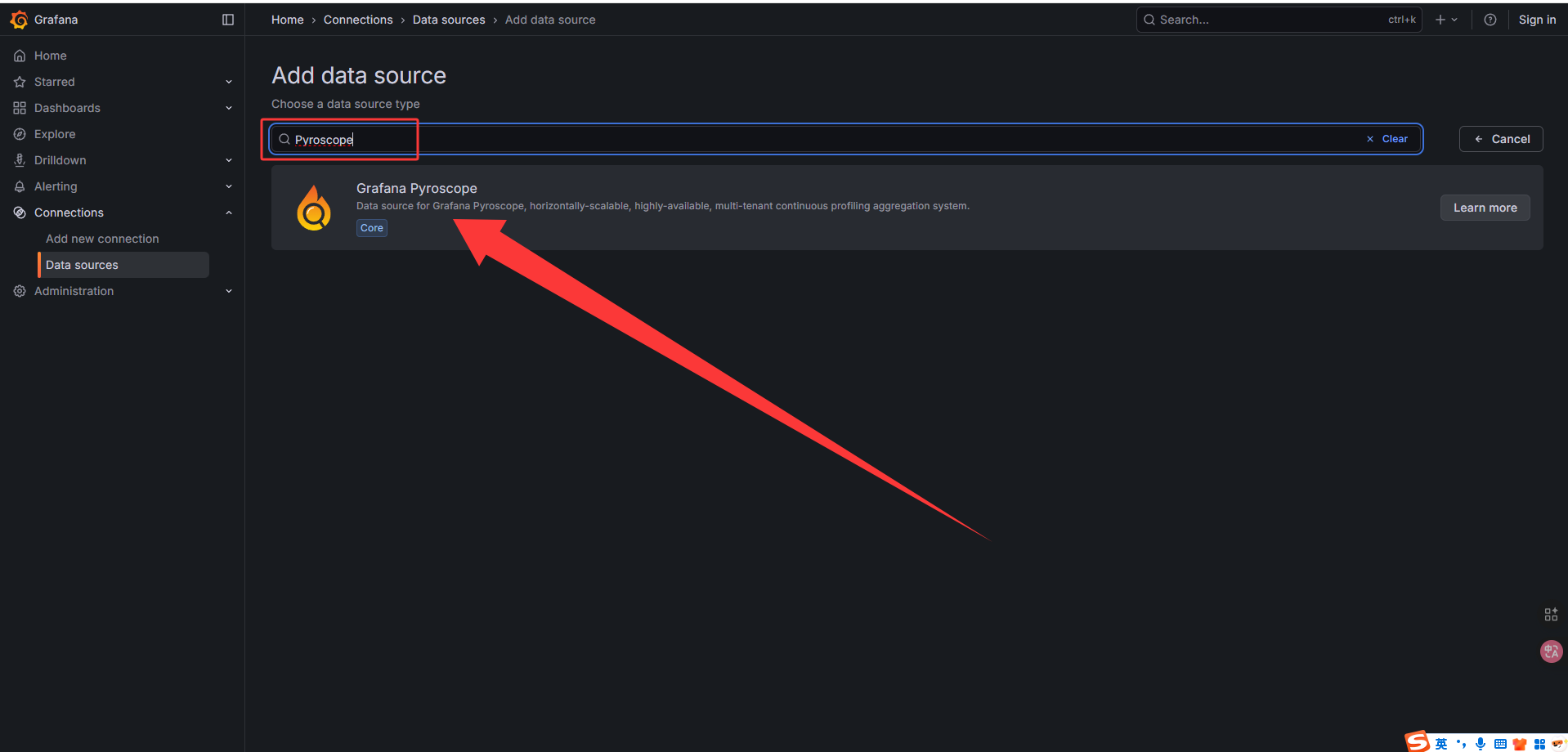
配置如下:
| 字段 | 值 |
|---|---|
| Name | Pyroscope |
| Type | Pyroscope |
| URL | http://pyroscope:4040 |
保存后点击 “Test connection” 验证连接成功。
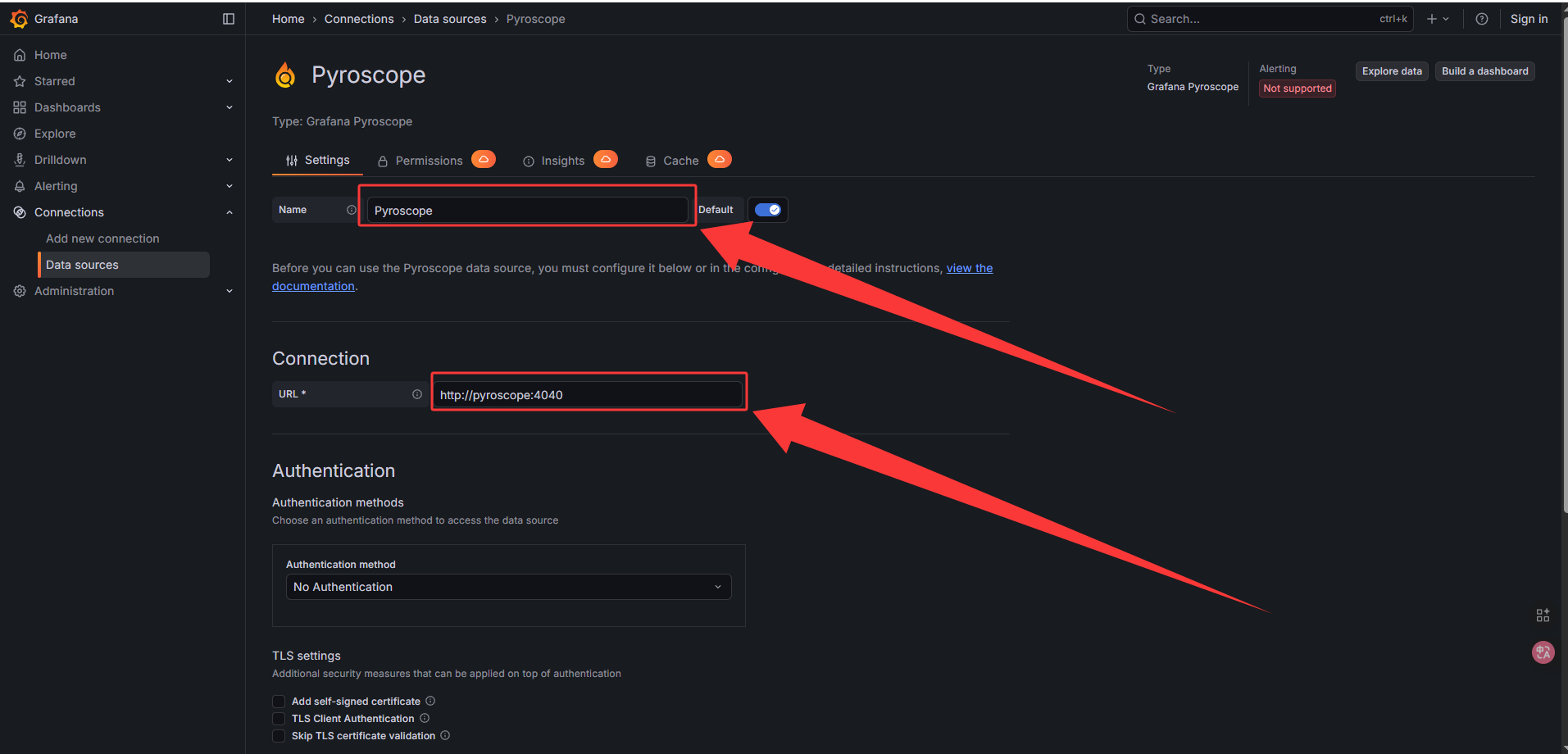
——3——
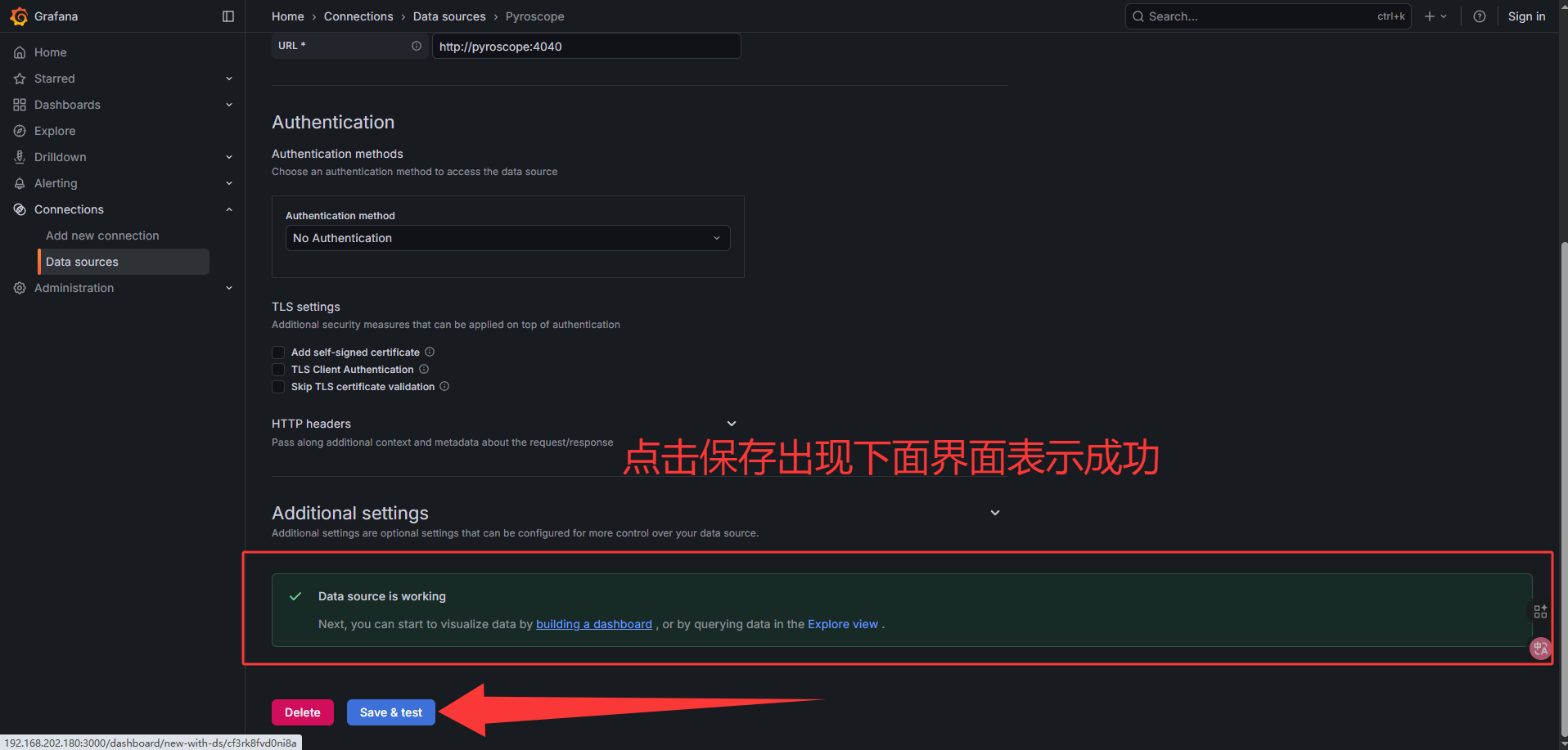
——4——
🔥 查看性能数据
在浏览器中打开: 👉 http://localhost:3000/a/grafana-pyroscope-app/profiles-explorer 即可进入 Profiles Drilldown 界面,查看和分析性能火焰图。
🧩 可选:添加应用数据采集(详见功能预研)
举例:Python 应用
pip install pyroscope-io代码中添加:
import pyroscope
pyroscope.configure(
application_name="myapp",
server_address="http://<your_server_ip>:4040"
)运行程序后,Grafana 就能看到持续采集的性能数据。
📦 停止与清理
停止服务:
docker compose down清理数据(如要重置):
sudo rm -rf ./pyroscope-data三、功能预研
1、Go语言应用接入 Pyroscope(代码示例)
Pyroscope 官方提供了 Go SDK(pyroscope-go),支持持续采集 CPU、内存、锁竞争等性能数据。
🔧 安装依赖
go get github.com/grafana/pyroscope-go它是 Pyroscope 的 Go 客户端 SDK(依赖包)。
也就是说:
- 你在服务器上部署的 Pyroscope 服务端(Docker 或二进制)
- 你在应用代码中引入
pyroscope-go(客户端 SDK) - 应用运行时会自动把性能数据(CPU、内存占用、函数调用栈)上传到 Pyroscope 服务器
结构上可以这样理解:
[Go 应用 + pyroscope-go SDK] ---> [Pyroscope 服务器 :4040] ---> [Grafana 可视化分析]
所以
go get就是下载并注册这个依赖包到你的项目go.mod中。
看了下上面的命令新版本不支持,采用如下方式可以:
1️⃣ 新建项目目录
mkdir -p /workplaces/golang/pyroscope-demo
cd /workplaces/golang/pyroscope-demo2️⃣ 初始化 Go 模块
go mod init pyroscope-demo执行后会生成一个文件:
go.mod内容大概像:
module pyroscope-demo
go 1.223️⃣ 获取 Pyroscope 客户端依赖
go get github.com/grafana/pyroscope-go现在这条命令就不会报错了 ✅ Go 会自动下载依赖包到 $GOPATH/pkg/mod/ 下。
🚀 在应用中启用持续性能剖析
——以一个持续输出Hello GO !!!的代码为例,分析pyroscope对服务器CPU的监控
package main // 定义主包,Go 程序入口必须是 main 包
import (
"fmt" // 用于格式化字符串
"time" // 提供时间相关功能,例如 sleep
"github.com/grafana/pyroscope-go" // Pyroscope Go 客户端,用于持续性能采集
)
func main() {
// 启动 Pyroscope Agent,用于向 Pyroscope 服务器持续上传性能数据
pyroscope.Start(pyroscope.Config{
ApplicationName: "my-go-app", // 设置应用名称,在 Pyroscope 仪表盘中显示
ServerAddress: "http://192.168.202.180:4040", // Pyroscope 服务器地址,数据会发送到这里
})
// 模拟业务逻辑的无限循环
for {
doWork() // 调用 doWork 函数,执行模拟负载
}
}
// doWork 模拟业务逻辑的工作负载
func doWork() {
// 循环执行一段耗 CPU 的操作
for i := 0; i < 10000000; i++ {
// 每次循环格式化一个字符串,但不保存结果
// 这里主要为了消耗 CPU,使 Pyroscope 能采集到活跃函数的 CPU 使用情况
_ = fmt.Sprintf("Hello GO !!! -%d-", i)
}
// 每次循环完成后暂停 1 秒,模拟业务中的等待/休眠
time.Sleep(1 * time.Second)
}✅ 运行后效果
go run main.go- 代码会自动将性能数据(CPU使用、函数耗时)持续推送到 Pyroscope Server
- 你可以在 Grafana → Profiles Explorer 中看到
my-go-app的火焰图 - 该数据是实时 + 历史可追溯的
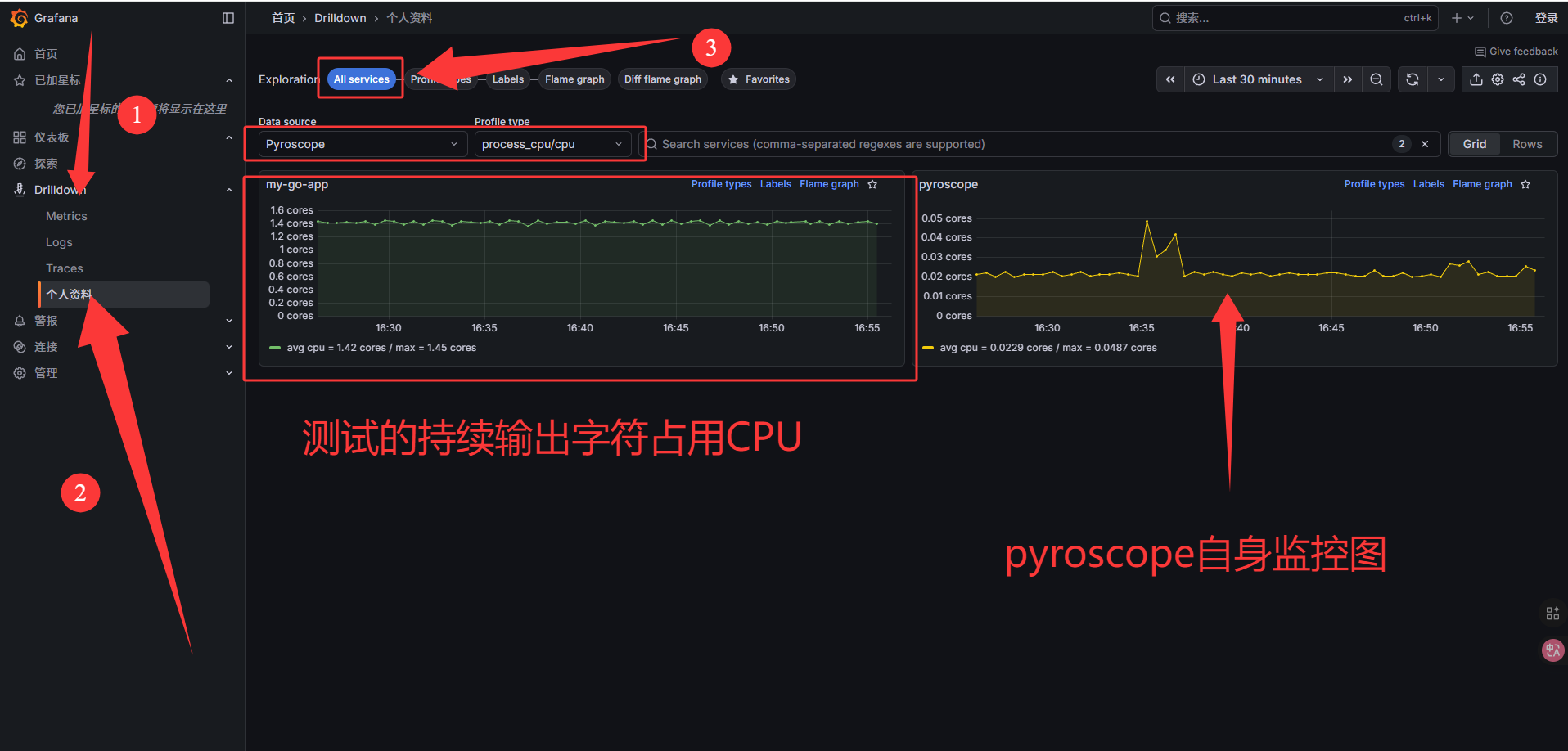
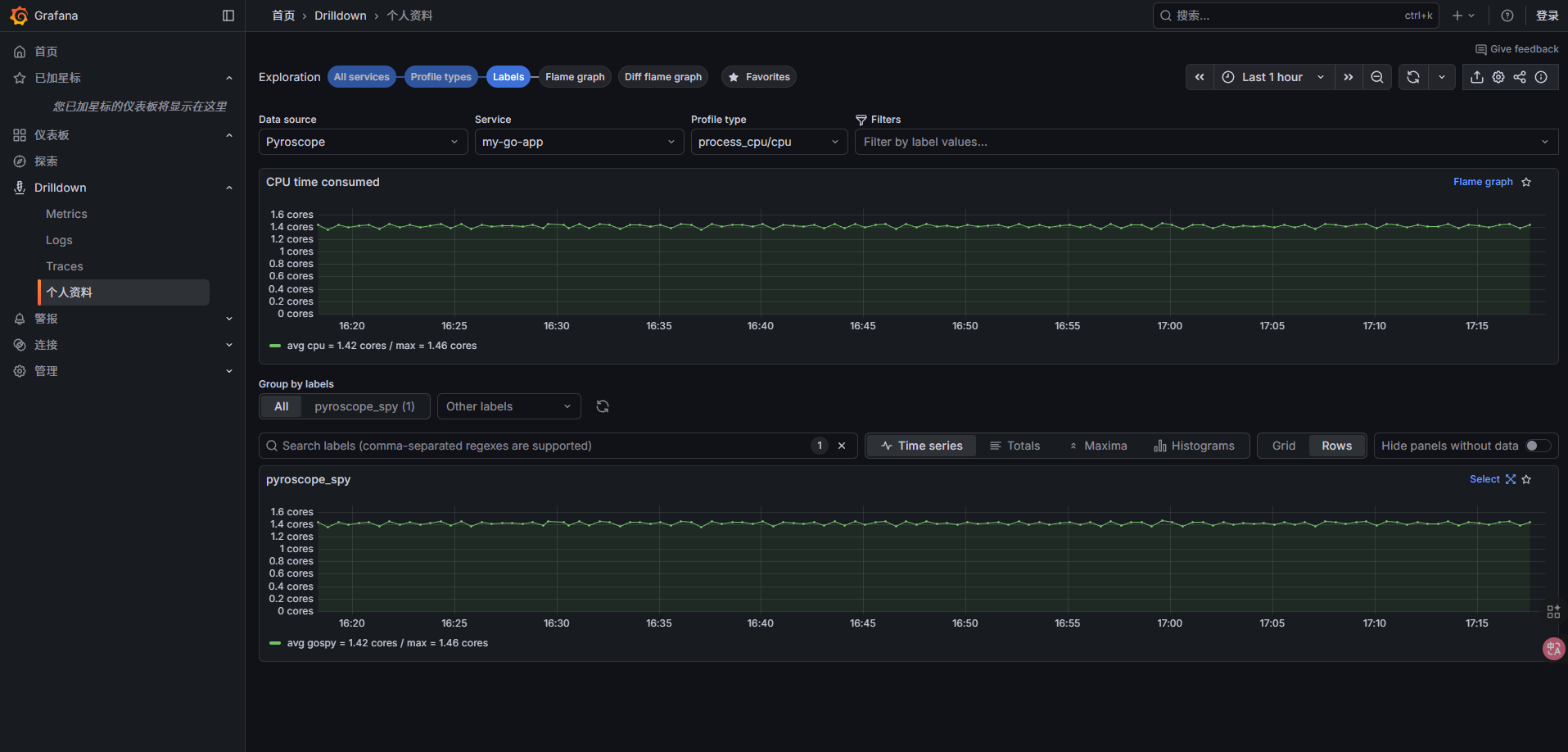
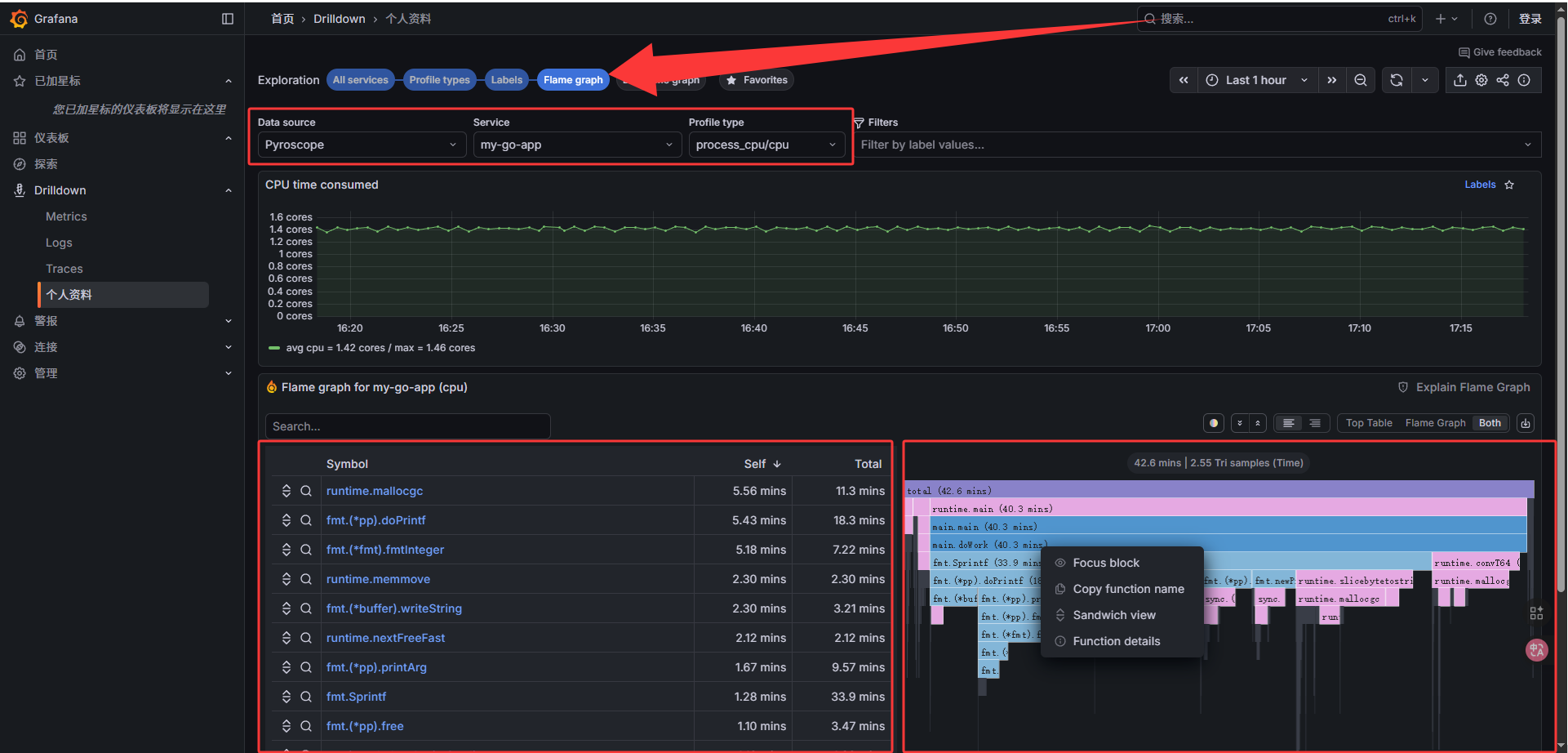
Grafana Pyroscope 界面介绍
| 界面元素 | 说明 |
|---|---|
| All services | 列出所有被 Pyroscope 采集的应用服务 |
| Profile types | 选择采集类型:CPU、内存、goroutine 等 |
| Labels | 根据自定义标签过滤或分组应用/函数 |
| Flame graph | 火焰图视图,展示函数调用耗时 |
| Diff flame graph | 对比两个时间段或版本的性能差异 |
| Favorites | 收藏的函数或应用,方便快速访问 |
——5——
——6——
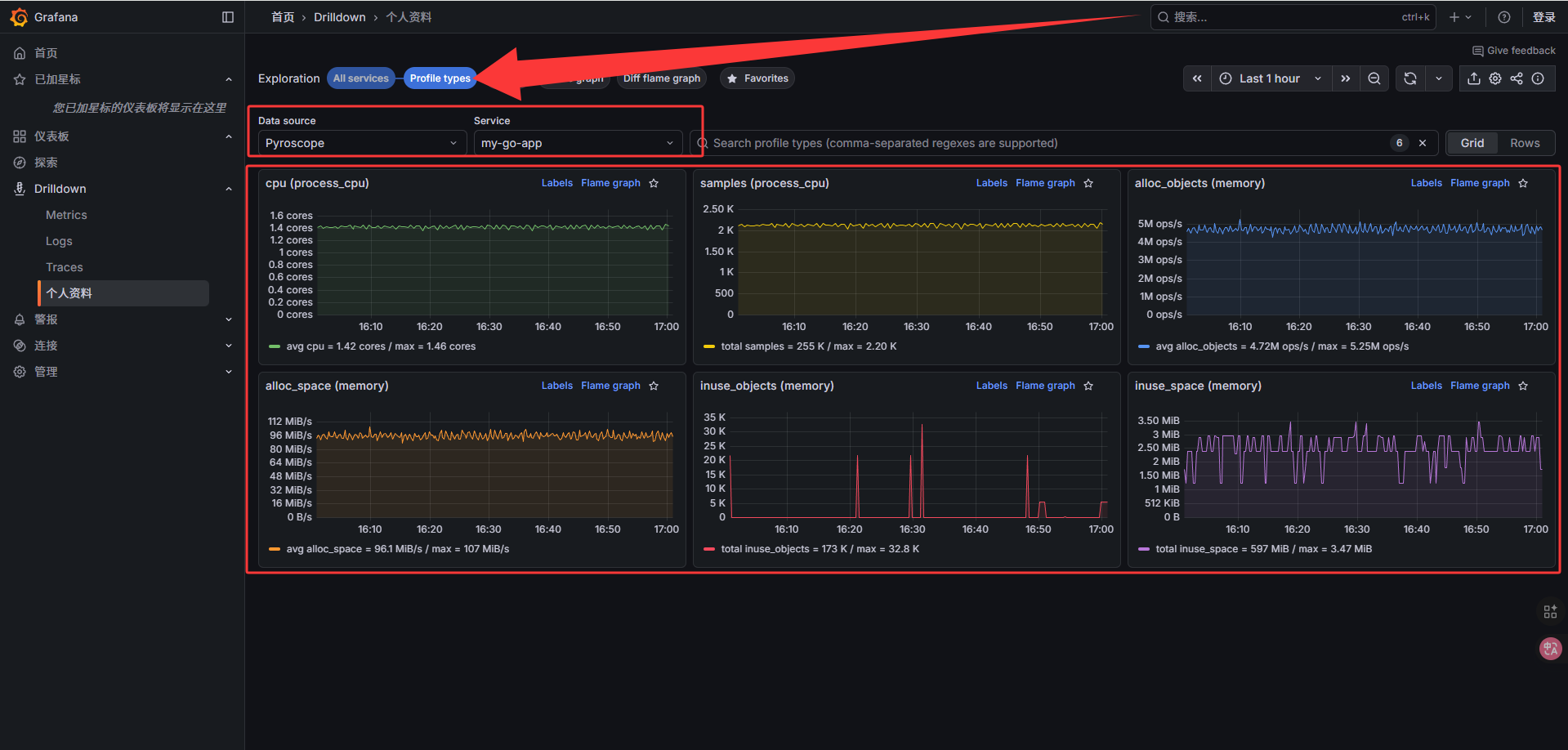
| 指标 / 类型 | 中文翻译 | 实际数据 | 简要说明 |
|---|---|---|---|
| cpu (process_cpu) | CPU(进程 CPU) | avg = 1.42 cores / max = 1.46 cores | 当前进程消耗的 CPU 核心数,平均和峰值 |
| samples (process_cpu) | 样本数(进程 CPU) | total = 255 K / max = 2.20 K | 采样到的 CPU 栈样本总数及单次采样最大值 |
| alloc_objects (memory) | 分配对象数(内存) | avg = 4.72M ops/s / max = 5.25M ops/s | 每秒分配的对象数量,平均和峰值 |
| alloc_space (memory) | 分配空间(内存) | avg = 96.1 MiB/s / max = 107 MiB/s | 每秒分配的内存大小,平均和峰值 |
| inuse_objects (memory) | 使用中对象数(内存) | total = 173 K / max = 32.8 K | 当前还在使用的对象数量及峰值 |
| inuse_space (memory) | 使用中空间(内存) | total = 597 MiB / max = 3.47 MiB | 当前持有内存总量及峰值 |
——7——
——8——
——9——
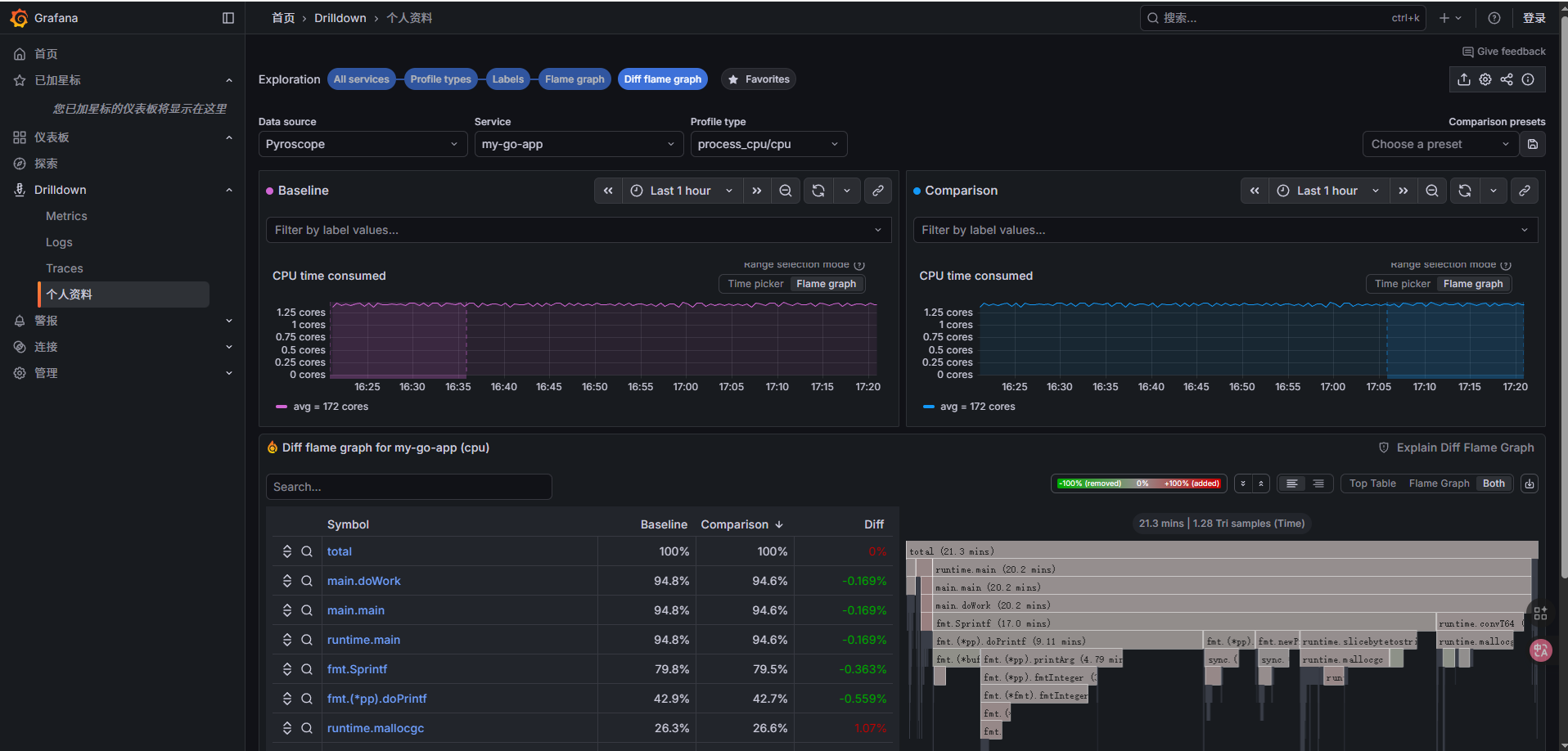
1️⃣ 什么是 Diff Flame Graph
- Diff Flame Graph 是 Pyroscope 的一个可视化工具,用于对比 同一函数或模块在不同时间段/版本的性能变化。
- 它基于 Flame Graph(火焰图),在原有的调用栈基础上增加了颜色标记:
- 红色:当前时间段耗时比基准增加 → 性能下降
- 蓝色:当前时间段耗时比基准减少 → 性能提升
一句话理解:它帮你看到函数或模块在不同时间或版本之间的性能差异。
2️⃣ 怎么用
方法一:自动选择
- 点击 Auto-select,系统自动选择最近两个时间段生成对比图。
- 优点:快速,无需手动操作。
方法二:预设范围
- 选择 Choose a preset,例如:
- 最近 1 分钟 vs 最近 5 分钟
- 当前版本 vs 上一版本
- 系统会按预设生成差异火焰图。
方法三:手动选择(推荐精确分析)
- 在 Baseline Flame Graph 上用鼠标拖拽选择参考时间段。
- 在 Comparison Flame Graph 上选取你想对比的时间段。
- Pyroscope 生成 Diff Flame Graph,高亮显示性能变化。
3️⃣ 使用场景
- 性能回归测试:发布新版本前,看看哪个函数耗时变多。
- 热点函数分析:判断优化是否有效,哪些模块消耗变大。
- 团队研发监控:快速定位性能异常或变化点。
2、Pyroscope 架构角色:客户端 & 服务端
Pyroscope 本身分为两部分:
| 角色 | 名称 | 功能 | 部署位置 |
|---|---|---|---|
| Agent / SDK | pyroscope-go / pyroscope-py / alloy-agent | 嵌入到应用中,采集性能数据 | 每台应用服务器 |
| Server | grafana/pyroscope | 存储和可视化性能数据 | 中心化部署(1台即可) |
也就是说:
✅ 你现在部署的 Pyroscope 容器是服务端
🧩 而你的 Go/Python 程序中引用 SDK 就是客户端(Agent)
3、企业级多服务器部署方式(核心思路)
企业环境通常分为两种模式👇
模式A:集中式 Pyroscope Server(推荐)
- 各服务器部署应用 + Pyroscope Agent(SDK或eBPF)
- 所有 Agent 上报到同一个 Pyroscope Server
- 统一存储、可视化分析
📊 架构示意
[App Server 1] --┐
[App Server 2] --┤ → Pyroscope Server (中央节点)
[App Server 3] --┘
↓
Grafana Dashboard✅ 优点:
- 中央管理,统一监控多个服务性能
- Grafana 一站式查看火焰图
- 节省维护成本
⚠️ 注意:
- Pyroscope Server 建议使用持久化存储(挂载 volume)
- 网络需要保证 Agent → Server 的 HTTP 访问
4、采集内容配置
通过 SDK 设置采集类型
- Go 里可以设置:
pyroscope.Start(pyroscope.Config{
ApplicationName: "myapp",
ServerAddress: "http://localhost:4040",
ProfileTypes: []pyroscope.ProfileType{pyroscope.ProfileCPU, pyroscope.ProfileHeap},
})默认是 CPU 采样,你可以添加 heap(内存)、goroutine、mutex 等。
自定义 Label/Tag
- 可以在业务逻辑中标记,例如不同服务或功能模块:
pyroscope.Tag("team", "A")
pyroscope.Tag("feature", "login")采样间隔和精度可调
- 默认是 10ms 一次采样(CPU),可以调快或慢,控制性能开销。
pyroscope.Config{
SampleRate: 1000, // 每秒采样 1000 次
}按应用或模块分组
ApplicationName 是数据聚合单位,不同团队或服务可以分开。
5、服务器直接部署 Agent 方案
用 Grafana Alloy 作为 Pyroscope 客户端
Alloy eBPF 需要 Linux 内核 ≥ 4.19 才能运行。3.10(CentOS 7 默认内核) → eBPF 无法启动。
(1)Alloy 是什么
Grafana Alloy = 新版 Grafana Agent
→ 官方说明:Grafana Agent will EOL on 2025-11-01
→ Alloy 是基于 OpenTelemetry Collector 的新一代采集器
(2)部署结构
[被监控服务器或容器]
↓
Grafana Alloy (eBPF profiling)
↓
[Pyroscope / Phlare Server]
↓
Grafana 可视化(3)部署步骤
1️⃣ 下载并运行 Grafana Alloy
docker run -d \
--name grafana-alloy \
--privileged \
--pid=host \
--network=host \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /etc/alloy:/etc/alloy \
grafana/alloy:latest \
run /etc/alloy/config.river⚠️ 注意:
--privileged 和 --pid=host 是 eBPF profiling 必须的
✅ --privileged 赋予容器 完全的主机权限。
eBPF profiling 需要访问内核级别的性能事件和
/sys/kernel/debug,没有这个选项无法读取 CPU 栈信息。
⚠️ 所以在监控宿主机层面时,这一项是必须的。
✅ --pid=host
让容器与宿主机共享 进程命名空间。
Alloy 才能看到宿主机上的所有进程(PID),进行性能剖析。
否则只能看到容器内部自己的进程。
✅ --network=host
让容器共享宿主机的 网络栈。
这样 Alloy 可以直接通过宿主机网络与 Pyroscope / Phlare 通信,而不用额外映射端口。
(因为它默认用 HTTP 向服务端上报数据)
/etc/alloy/config.river是配置文件路径
/var/run/docker.sock 是什么?
这个文件是 Docker 守护进程(Docker Daemon)提供的 Unix 套接字接口(socket)。 它相当于是 Docker 的“大门”或“遥控器”,允许程序通过它来:
- 列出当前运行的容器;
- 查看每个容器的状态;
- 获取容器的 CPU、内存、网络等性能指标;
- 启动 / 停止容器;进入容器、查看日志等。
也就是说: 👉 挂载了 /var/run/docker.sock 的容器,就能远程控制整个宿主机的 Docker 环境。
当你运行:
-v /var/run/docker.sock:/var/run/docker.sock这行命令让 Pyroscope Agent 容器 拥有访问宿主机 Docker 守护进程的能力。 于是它就可以做到👇:
- 自动扫描宿主机上运行的所有容器;
- 识别每个容器的名称、ID、镜像、CPU/内存占用;
- 定期采集每个容器的性能 Profile 并上传到 Pyroscope Server。
🔸 所以,它不需要进入每个容器内部;
🔸 只要有 /var/run/docker.sock,它就能从“外部”监控所有容器。
2️⃣ 创建配置文件 /etc/alloy/config.river
配置示例(不支持注释,否则报错)
pyroscope.write "default" {
receiver {
type = "pyroscope"
url = "http://192.168.202.180:4040"
}
}
pyroscope.ebpf "system" {
enabled = true
languages = ["python", "go"]
}
discovery.docker "containers" {
host = "unix:///var/run/docker.sock"
}
pyroscope.ebpf "containers" {
targets = discovery.docker.containers.targets
forward_to = [pyroscope.write.default.receiver]
}默认通过 Alloy + eBPF,你能直接采集的核心指标是 CPU、Heap、Goroutine。 如果想监控更多(如网络 I/O、文件操作、特定函数延迟等),需要:
- 额外配置 eBPF 脚本
- 或者 在应用代码里埋点(SDK instrumentation)
(4)验证是否成功
运行:
docker logs -f grafana-alloy看到:
level=info msg="ebpf profiler started"
level=info msg="sending profiles to http://192.168.202.180:4040"说明 Alloy 已经正常采集并上传。
然后进入你的 Grafana → Data Source → Pyroscope(或 Phlare) 就能看到 Alloy 上传的 CPU Profiling 数据。
(5)可选:监控单个容器
如果你只想采集某个容器的性能,而不是整个宿主机:
- 用
docker run的--label pyroscope=true - 然后在配置文件中通过 label selector 过滤:
discovery.docker "containers" {
filters = [{ name = "label", values = ["pyroscope=true"] }]
}6、总结对比:两种部署方式
| 部署方式 | 优点 | 适用场景 |
|---|---|---|
| 方式①:在应用代码中引入 Pyroscope SDK(如 Go、Python) | 精确到函数级 | 研发测试、性能优化 |
| 方式②:用 Agent 容器监控整机或容器 | 无需改代码,一键部署 | 运维环境、全局监控 |
三、常见问题
1、Pyroscope报错:This program can only be run on AMD64 processors with v2 microarchitecture support.
解决办法:
尝试更改 CPU 架构:在虚拟机设置中尝试不同的 CPU 类型——现在是kvm,改成hosts
2、Pyroscope权限管控问题
Pyroscope 数据隔离方式
Pyroscope 是性能采集工具,它的数据是按 ApplicationName 来区分的:
- 每个研发人员或每个项目可以给应用设置不同的
ApplicationName,例如: pyroscope.Start(pyroscope.Config{
ApplicationName: “teamA-service1”,
ServerAddress: “http://pyroscope.company:4040”,
}) - Pyroscope 自身没有复杂权限控制(开源版),所以 谁能看到哪些应用 主要靠 Grafana 的权限来控制。
待解决和需要考虑的问题:
1、权限问题
2、研发实际项目代码测试监控
3、告警部署测试
3、分析对比Pyroscope与其他企业级架构方案产品
1) Pyroscope(Grafana Pyroscope / OSS)
优点
- 开源、可自建,能直接与 Grafana 整合(Pyroscope 数据源、Pyroscope → Grafana 插件)。适合想把 profiling 纳入已有 Grafana 平台的团队。Grafana Labs
- 支持多语言 SDK(Go/Python/Java 等)和常见 profile 类型(CPU/heap/goroutine 等),仪表盘支持 flamegraph、diff、标签过滤等。Grafana Labs+1
- 存储与压缩做得较好,面向长期保存 profiling 数据(能做历史对比)。Grafana Labs
缺点 / 注意点
- 开源版在大型、跨机房部署时需要自己设计聚合/HA/多租户方案(可配合 Phlare/Mimir 等上层组件)。Grafana Labs
- 访问控制、企业级细粒度权限和托管支持不如 SaaS 厂商(例如 Datadog)的商业版。
适合场景
- 希望自建、对成本敏感、已有 Grafana 生态,想把 profiling 与现有监控合并的团队。
2) Parca(OSS,Kubernetes/infra-first)
优点
- 针对基础设施做了很多优化,强调零侵入/zero-instrumentation(eBPF +自动采集),对大规模 K8s 环境友好。Parca
- 设计为面向 infra-wide profiling,便于把整机/容器层面的采样统一收集并查询。
缺点
- 相比 Pyroscope,生态(Grafana 集成、语言 SDK 覆盖)成熟度略有差距(但快速发展)。
- 对于想要深度与 Grafana 一体化的团队,可能需要额外集成工作。
适合场景
- 大规模 Kubernetes 环境,偏重于在不改代码/不改应用的情况下实现全库 profiling。
3) Datadog Continuous Profiler(商业 SaaS)
优点
- 完整托管服务,界面与告警、APM、日志等整合紧密,开箱即用,适合不想运维采集系统的团队。提供强大的对比、查询和可视化功能。datadoghq.com+1
- 提供企业级支持与安全、权限控制、审计等功能。
缺点
- 成本较高(按主机/流量计费);数据归属在厂商,受限于 SaaS 策略。
- 若团队有严格合规/数据驻地要求,自建方案可能更合适。
适合场景
- 需要快速上线、愿意付费换取运维/集成成本节省的中大型企业。
4) Google Cloud Profiler(云托管)
优点
- 和 Google Cloud 服务(GKE、App Engine、Compute Engine)集成良好,适合在 GCP 上运行的服务;开箱支持分层查询和版本对比。Google Cloud Documentation+1
缺点
- 仅对在 GCP 上运行的负载最为方便;跨云或自建环境集成复杂或受限。
- 功能偏向云服务整合,而不是开源自部署。
适合场景
- 在 GCP 上有大量工作负载、希望使用云原生托管 profiling 的团队。
5) Grafana Phlare / Alloy / 聚合层(用于企业级扩展)
这些并不是直接替代 profiling 工具,而是 用于扩展、存储与聚合 的上层组件:
- Phlare:Grafana 的 profiling 存储方案,支持水平扩展与长期保留(支持 S3 后端)。适合大规模长期存储。Grafana Labs
- Alloy:统一 collector,能把 profiling(pyroscope.scrape)与 traces/metrics 统一采集,便于构建统一 telemetry pipeline。Grafana Labs+1
适合场景
- 需要企业级分区/多租户/长期存储和跨地域聚合的场景(模式 B 架构)。
为什么选择 Pyroscope(总结式理由)
- 开源且与 Grafana 生态整合紧密,如果你已经在用 Grafana,接入成本低,展示体验统一。Grafana Labs
- 支持多语言 SDK 与常见 profile 类型,可以直接在应用里集成做持续 profiling。Grafana Labs
- 可自建、可扩展:从单节点开始,遇到规模问题可以向 Phlare/Mimir/Alloy 等方向演进。对想“先试点、后扩展”的团队友好。Grafana Labs+1
作者
fffff@xf.nn





